CAP Theorem
I spent a fascinating 3-4 days last week at work with Greg Young learning more details around Domain Driven Design (DDD), Command Query Responsibility Segregation (CQRS) and Event Sourcing. This is definitely a topic that I will blog about soon. In the meantime, one of the areas touched upon was CAP Theorem which is sometimes referred to as Brewers Conjecture.
This was originally proposed by Eric Brewer back in 1998, and states that any distributed system can only achieve two of the following three properties:
- Consistency (C) – this means the system will always return the most up-to-date information e.g. any read of a record after it has been updated, must return the updated information
- Availability (A) – this means the system is available so that a non-failing node will return a response within a reasonable amount of time
- Partition Tolerance (P) – this means the service can survive a communication breakage that results in some nodes in a cluster being unable to communicate with other nodes. This is known as split brain
One of the fallacies of distributed computing is that networks are reliable – they are not. As such, any distributed system must be designed to handle network partitions. This means when designing a system, we will need a trade off between consistency and availability.
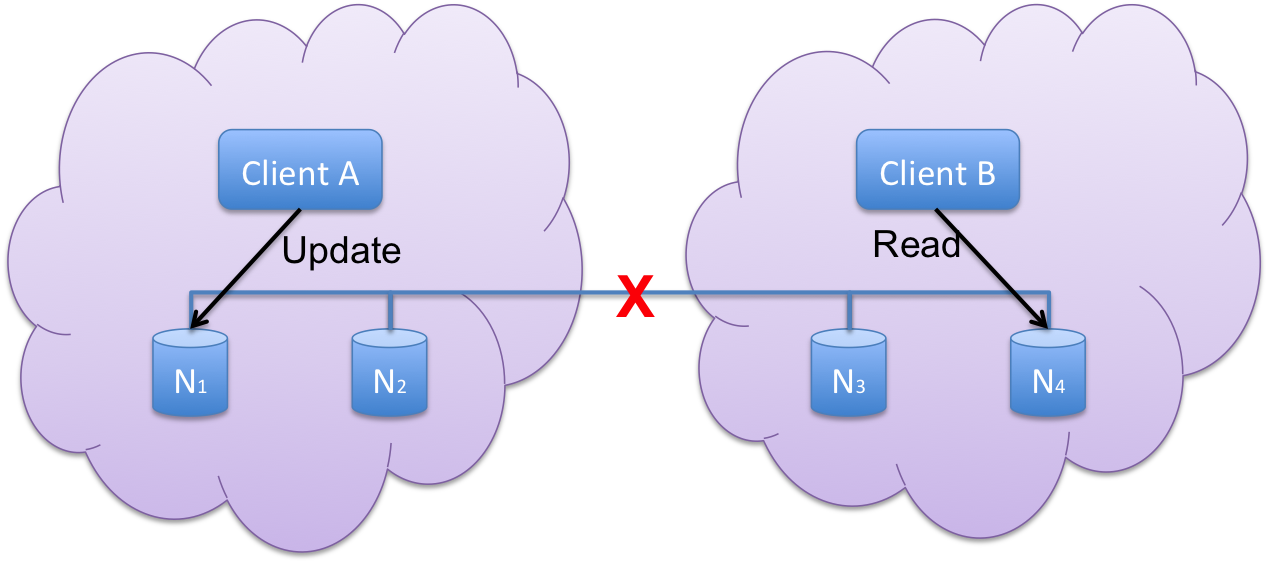
In the example above, data is distributed across 4 nodes. To be fully consistent, when Client A updates a record, Client B must be able to read that record, even when the read is made from a separate node. The problem occurs when there is a network partition, which prevents the updates being synchronized or replicated to the other data nodes.
In its simplistic form, there are two basic options. A system that mandates consistency will fail when Client B attempts to access the record. A system that mandates availability will succeed but return stale data when Client B attempts to access the record.
It is crucial to understand that this is not an either/or binary decision. Instead, there are patterns which allow a sliding scale of availability or consistency. A system as a whole will also consist of many services, and each of these may choose a different preference. This is based on factors such as risk and probability. In my current role, the view is to be consistent when we can, but when not possible we will choose availability. This is because the probability of multiple transactions taking place almost simultaneously on a specific record are extremely rare. When choosing to use local data to improve availability, a staleness indicator will be included. This would allow a transaction to be rejected if the perceived risk was high enough if transacting against stale data.